大型多模态模型 LLaMA-HR:兼顾高分辨率和速度
- 2025-11-09 19:31:54
一、背景介绍
在大型多模态语言模型(LMM)中提升输入图像的分辨率可以有效提升细粒度识别方面的能力(尤其场景文本识别,例如 TextVQA),这已成为一个共识,并且在许多模型中得到应用。本文中作者同样采用了提高分辨率的方式,而且进一步探索了如何在提升分辨率的同时避免过高的训练和推理代价。
对应的论文为:[2403.03003] Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
对应的代码库为:GitHub - luogen1996/LLaVA-HR: LLaVA-HR: High-Resolution Large Language-Vision Assistant
1.1 LLaVA-NeXT
在 LLaVA-NeXT: Improved reasoning, OCR, and world knowledge 中,LLaVA-NeXT 可以支持 672x672, 336x1344, 1344x336 的分辨率,像素数是 LLaVA-1.5 的 4 倍,LLaVA-1.5 的图像分辨率为 336x336。LLaVA-NeXT 采用高分辨率子图像+低分辨率整图的方案,高分辨率子图可以提供细粒度信息,有效降低模型的幻觉。LLaVA-NeXT 支持可配置的子图像分布,包括:{2×2,1×{2,3,4},{2,3,4}×1}。通过这种范式可以适配多种分辨率比例,如下图所示为 2x2 分布的情形:
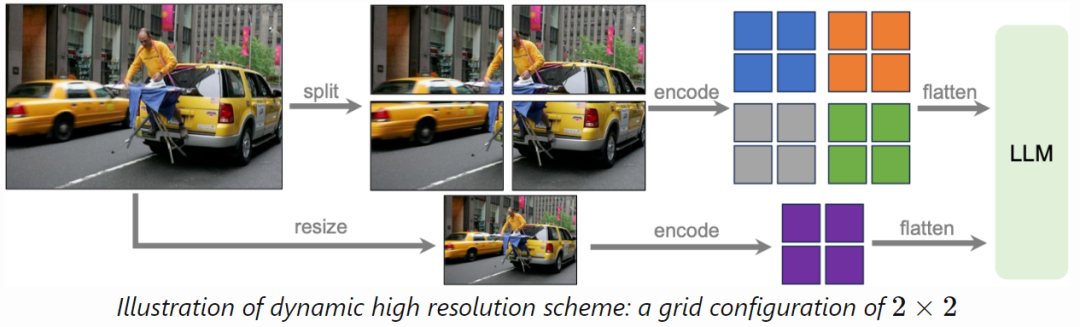
1.2 SPHINX
在 [2311.07575] SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models 中也采用了如上增加输入分辨率的方式,相应的可以将分辨率扩大到 762x762,如下图 Figure 4 所示:
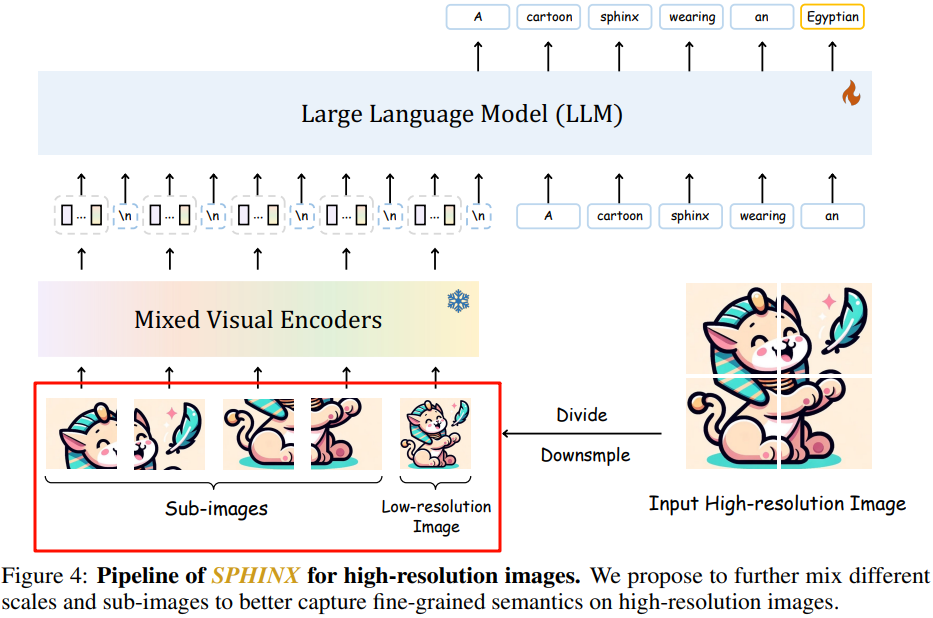
1.3 Monkey
在 [2311.06607] Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models 中类似,作者将分辨率扩大到 896x1244,如下图 Figure 2 所示:
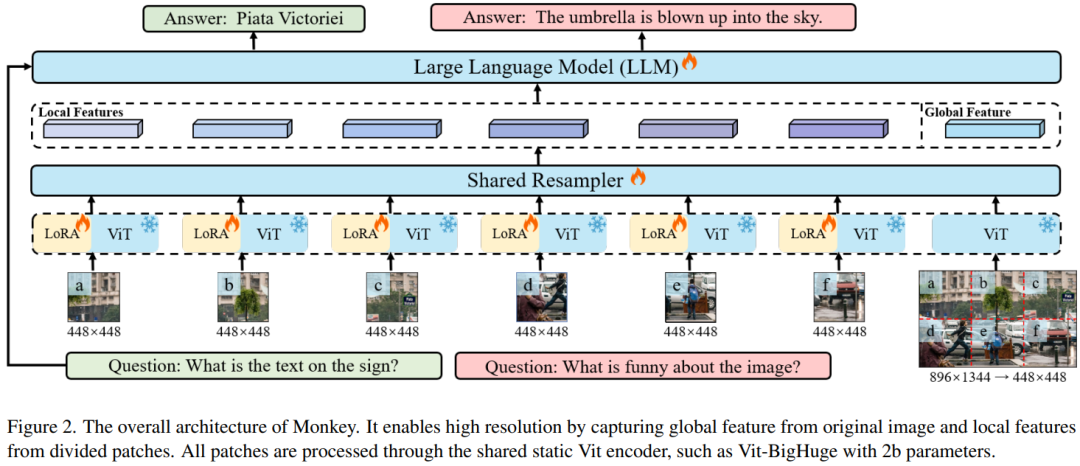
1.4 Claude-3
在 The Claude 3 Model Family: Opus, Sonnet, Haiku 中,作者也强调了其强大的多模态能力,如下图所示,可以准确识别图片中的手写文字,并将其格式化输出。作者提到,Claude-3 模型支持最大 10MB,8000x8000 像素的图片输入,并且建议避免输入低分辨率的小图像。同时作者也介绍,在进行 AI2D 评估时,对分辨率比较低的图像进行上采样,长边扩展到 800 像素,保持分辨率不变,性能提升了 3-4%。
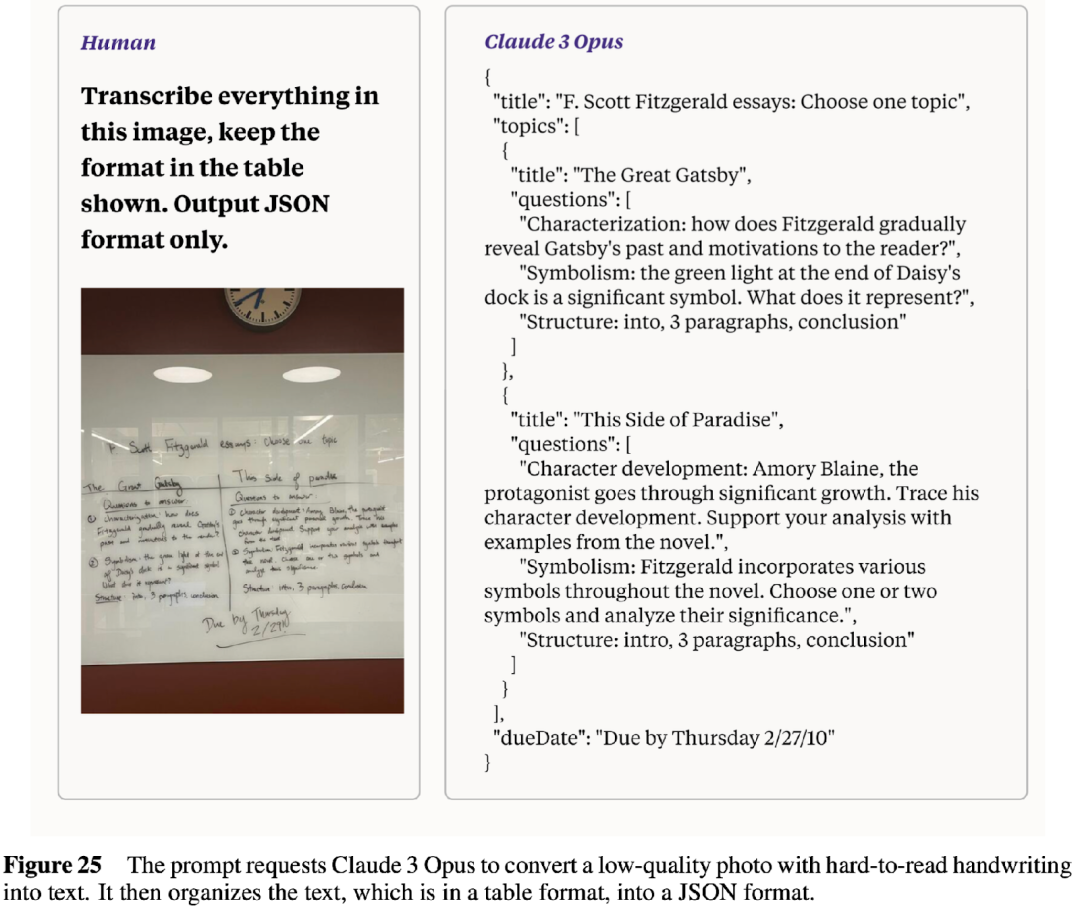
二、摘要
本文介绍的论文中,作者提出了一种混合分辨率融合方案(Mixture-of-Resolution Adaptation,MRA),具体来说,MRA 对不同分辨率的图像采用两个视觉通路,其中高分辨率视觉信息通过新的混合分辨率适配器(MR-Adapter)嵌入到低分辨率通路中。这种方式大大降低了 LMM 的输入序列长度,进而可以有效降低训练和推理时间。
为了验证这种方案的有效性,作者将其扩展到 LLaVA 模型中,新的模型称为 LLaVA-HR。在 11 个视觉语言任务上进行实验,结果表明 LLaVA-HR 在其中的 8 个任务上优于现有的 LMM。例如,在 TextVQA 任务上获得 9.4% 的提升。更重要的是,使用 MRA 时,LLaVA-HR 的训练和推理都非常高效,推理速度比 LLaVA-1.5 快 3 倍。
三、概述
3.1 训练、推理速度问题
如下图 LLaVA 1.5 所示,常见的 LMM 会使用 ViT 系列模型(比如 CLIP)将图像转换为视觉表征(Vision Token),ViT 常见的方式为一个 14x14 的 Patch 转换为一个 Token,对于 336x336 的图像而言,其最终会生成 (336/14)*(336/14)= 576 个 Token,而当分辨率上升到 1022x1022 时,将产生 5329 个 Token,Token 数扩大了将近 10 倍,导致极大的训练和推理成本。此外,5329 个 Token 甚至超过了常见 LLM 的上下文窗口长度(2K、4K),也导致其很难落地。
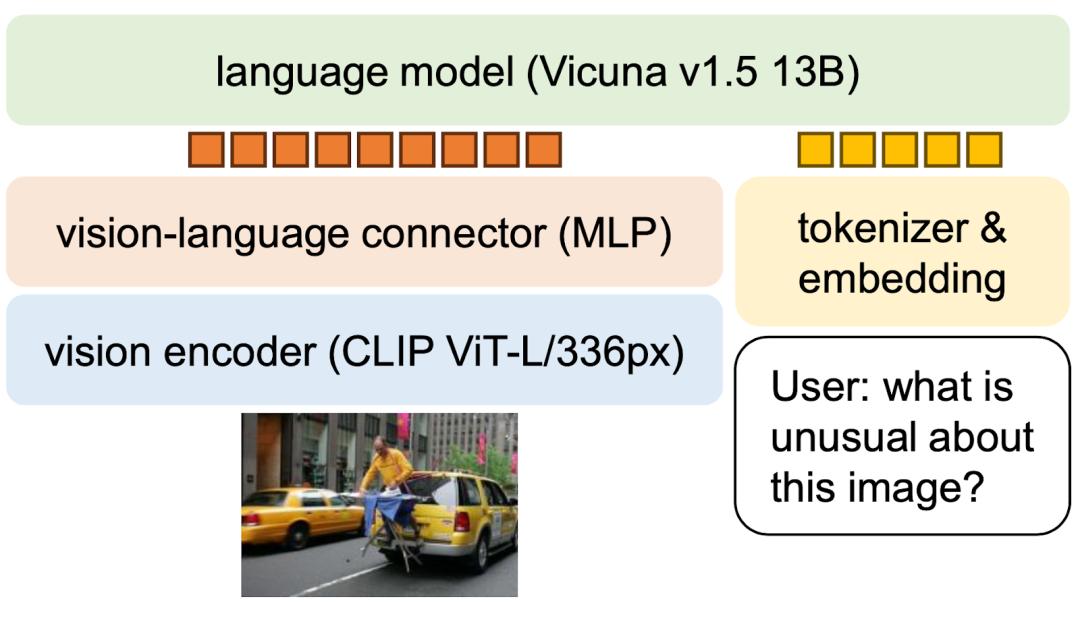
3.2 本文方案
如下图左侧为常见的 LLM 方案,通常只有一个 Image Encoder,如下图右侧所示为本文的 Mixture-of-Resolution 方案,其包含两个 Image Encoder,相当于额外增加一个 Image Encoder,用于提取高分辨率视觉表征,并将其融入到低分辨率的视觉表征中,以避免过大的视觉 Token 数。
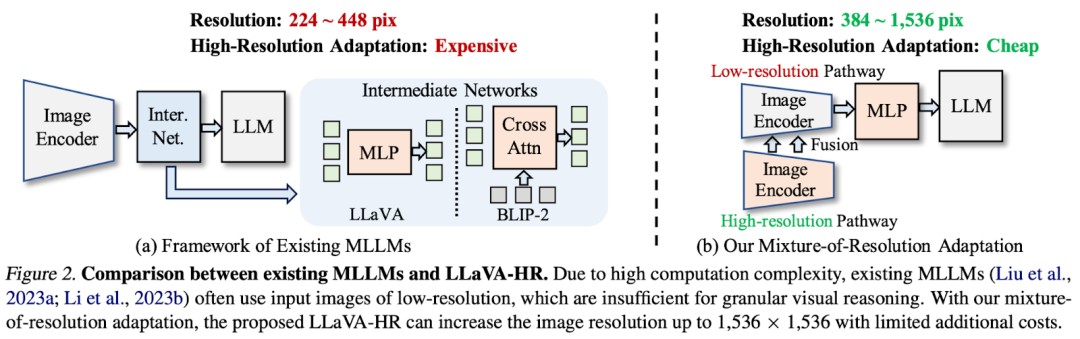
四、具体方案
4.1 两路视觉编码(Dual Visual Pathways)
如下图 Figure 3 所示,其包含低分辨率和高分辨率两路视觉编码,由于分辨率不同,也会导致生成不同形状的视觉特征,为了解决这个问题,作者针对不同分辨率采用了不同的下采样率,比如针对低分辨率采用的是 ViT,下采样率为 14,针对高分辨率图像,采用更高效的 CNN 模型,下采样率为 32,也就是 448x448 的图像和 1024x1024 的图像都生成了 32x32 个视觉特征。在生成低分辨率视觉特征时,会将高分辨率视觉特征融入到 ViT 的不同 Stage 中。
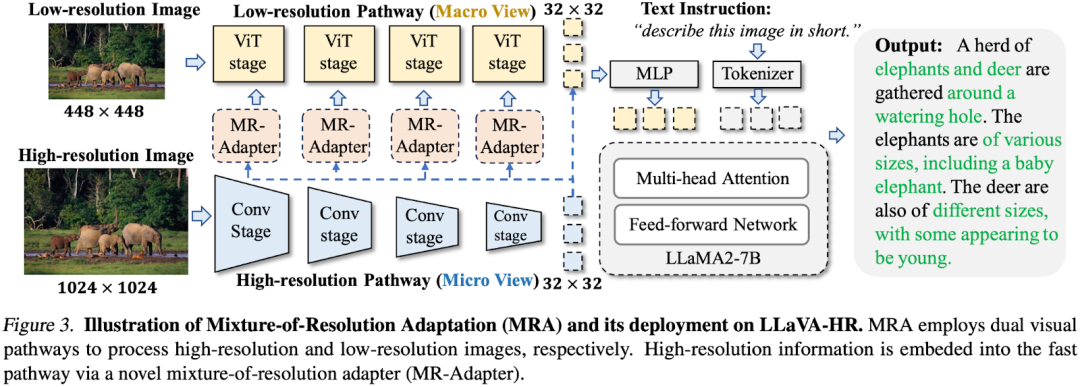
4.2 混合分辨率融合(Mixture-of-Resolution Adapter)
具体的融合公式如下公式和图 Figure 4 所示,高分辨率视觉表征 Fvh 会先经过 MLP Block,低分辨率视觉表征 Fvl 会先经过 Conv Block,然后经过 Gate,最后再将几个表征融合。
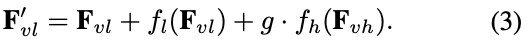
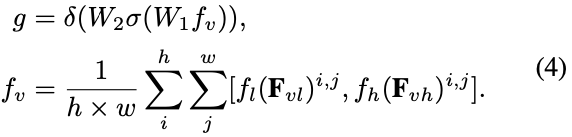
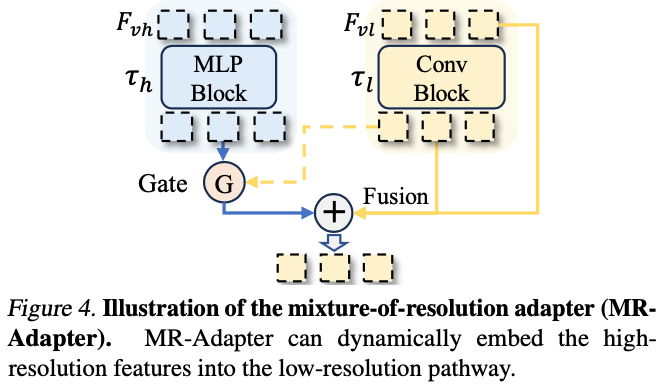
PS:从上述 MR-Adapter 的结构可以看出,LLaVA-HR 的示意图很容易引起歧义,更贴切的表示应该是下述的方式:
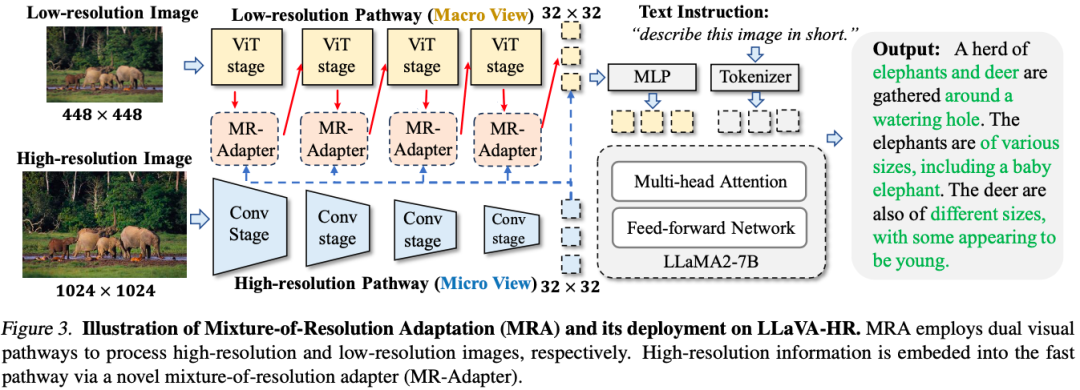
4.3 模型训练(The Deployment on MLLM)
作者将 MR-Adapter 扩展到了 LLaVA-1.5 中,融合后的模型称为 LLaVA-HR。该模型的训练包含两个阶段。
4.3.1 低分辨率预训练
和 LLaVA 以及 LLaVA-1.5 类似,目的是优化投影层(projector),以实现视觉表征和 LLM 的 Word Embedding 对齐。在此阶段,image encoder 和 LLM 都保持冻结,并且未插入 MR-Adapter,两路视觉特征直接融合到一起。(两个 image encoder 输入分辨率都比较低,分别为 336x336 和 384x384)
4.3.2 高分辨率指令对齐
在此阶段,作者将高分辨率 image encoder 的分辨率从 384x384 扩展到 1024x1024,同时将低分辨率 image encoder 的分辨率从 336x336 扩展到 448x448,同时会将 MR-Adapter 融入到模型中,在此阶段整个模型都会解冻进行训练。
4.4 实现细节(Implementation Details)
在 LLaVA-HR 模型中,作者使用 CLIP-ViT-L 和 CLIP-ConvNeXt-L 作为 image encoder。在 LLaVA-HR-X 中,作者使用 CLIP-ConvNeXt-XXL 替换了 CLIP-ConvNeXt-L。同时 MR-Adapter 只作用在 ViT 的最后 3 个 Stage。
和 LLaVA-1.5 一样,作者也是首先使用 LCS-558K 预训练 LLaVA-HR,然后在指令对齐阶段使用 665K 的指令数据集。
五、实验
5.1 定量分析(Quantitative Analysis)
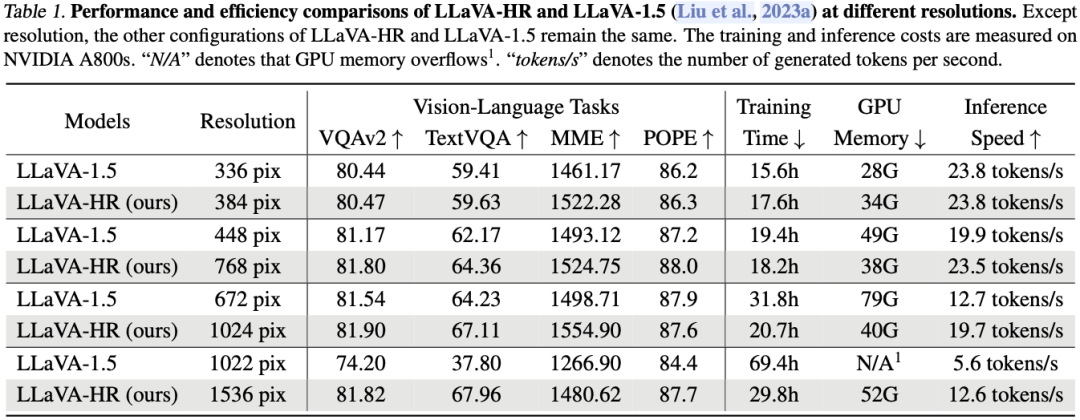
如下图 Table 1 所示,随着分辨率的增加,LLaVA-1.5 的训练速度和推理速度下降非常明显,而 LLaVA-HR 相对不太明显,当 LLaVA-1.5 使用 1022x1022 分辨率,LLaVA-HR 使用 1536x1536 分辨率时,LLaVA-HR 的训练和推理速度都是 LLaVA-1.5 的两倍多。大部分情况下 LLaVA-HR 的 VQAv2 和 POPE 指标都略好于 LLaVA-1.5;而 LLaVA-HR 在 TextVQA 和 MME 上的指标都明显优于 LLaVA-1.5,尤其是 TextVQA。
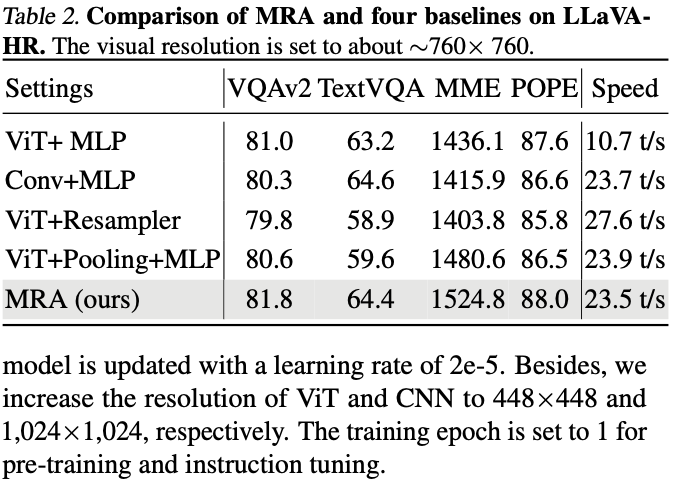
此外,作者也在 760x760 左右分辨率的情况下对比了其他的方案,比如 ViT+Resampler 和 ViT+Pooling+MLP 等,最终结果表明,本文方案在速度差不多的情况下获得了最优的效果:
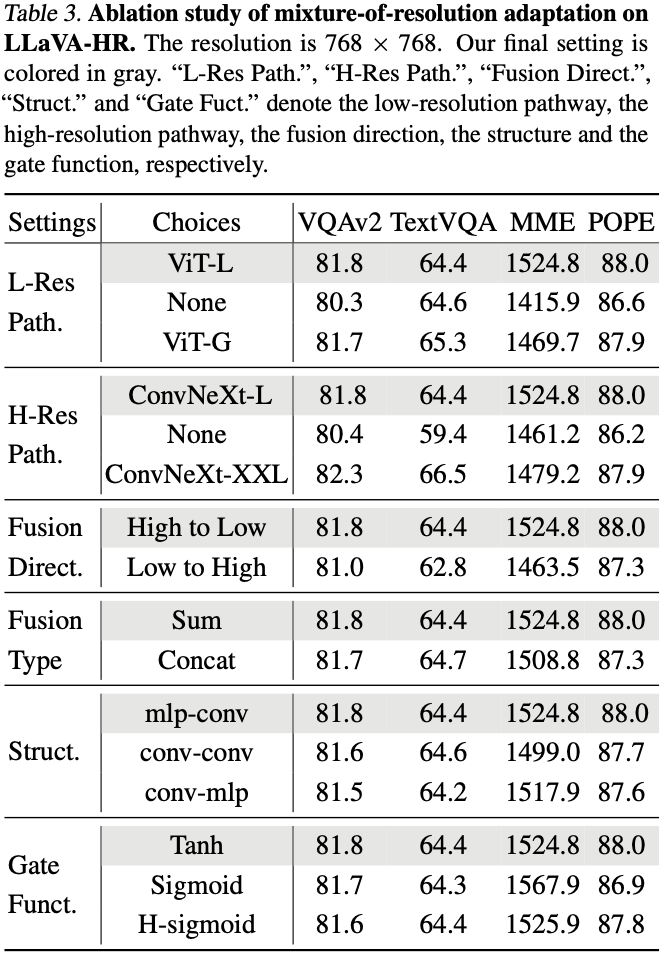
如下图 Table 3 所示,作者也对模型中的各个组件进行了消融实验,比如是否使用低分辨率、高分辨率分支,融合策略以及融合方向等。比如作者验证发现高分辨率 image encoder 使用 CLIP-ConvNeXt-XXL 替换 CLIP-ConvNeXt-L 可以获得更高的 VQAv2 和 TextVQA 分数,但 MME 指标却有明显降低:
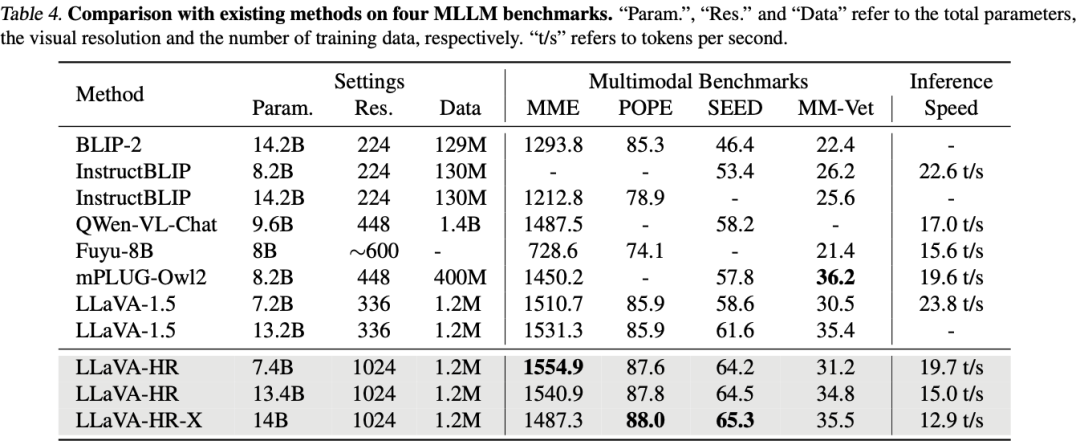
如下图 Table 4 所示,作者也与更多现有模型进行了对比:
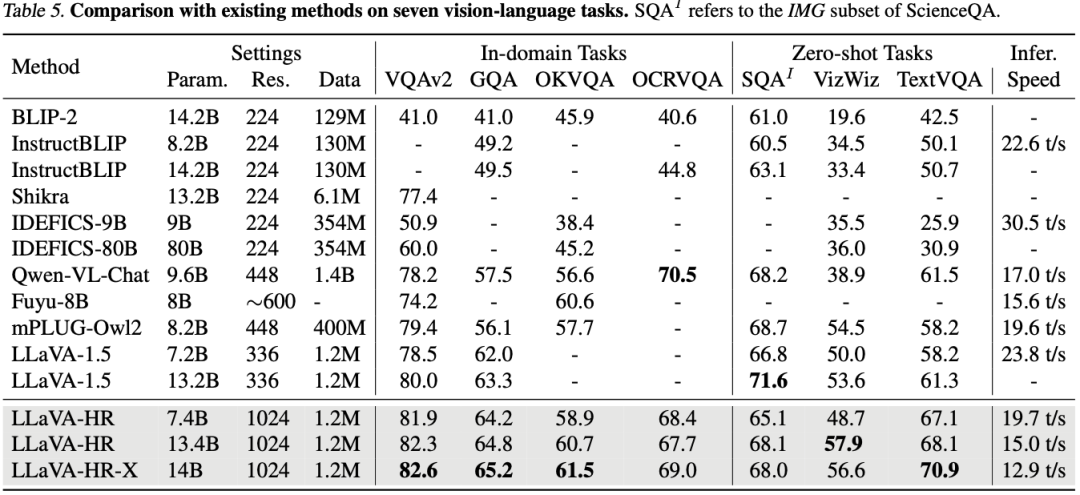
如下图 Table 5 所示,作者也在其他任务上进行了对比:
5.2 定性分析(Qualitative Analysis)
如下图 Figure 5 所示,作者也进行了部分定性分析,可以看出使用更高分辨率的 LLaVA-HR 比使用更低分辨率的 LLaVA-HR 或 LLaVA-1.5 获得更高的准确率:

六、参考链接
https://arxiv.org/abs/2403.03003
https://github.com/luogen1996/LLaVA-HR
https://llava-vl.github.io/blog/2024-01-30-llava-next/
https://arxiv.org/abs/2311.07575
https://arxiv.org/abs/2311.06607
https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
3. CogVLM: Visual Expert for Large Language Models 论文解读
8. SPHINX:多任务、多权重、多编码器、多分辨率混合的多模态大模型
9. Monkey:大分辨率+详细描述,多项 LMM SOTA
10. Florence-2:126M 图像,5.4B 视觉标注,0.77B LMM,多项 SOTA
2. LMM 视觉描述(Captioning)和定位(Grounding)数据集
3. LVIS-Instruct4V: Data is All You Need,12 评估 11 SOTA
1. Woodpecker: LMM 幻觉校正 - 论文解读

