LLMs 千面郎君:https://github.com/km1994/LLMs_interview_notes
LLMs九层妖塔:https://github.com/km1994/LLMsNineStoryDemonTower
NLP菜鸟逆袭记:https://github.com/km1994/AwesomeNLP
NLP 面无不过:https://github.com/km1994/NLP-Interview-Notes
1. 背景
最近发现很多粉丝私聊我,问我“Prefix LM与Causal LM区别”,故而,花费了大半天的时间钻研原理和起源,现在能够给出一个更为透彻明晰的关于Prefix LM与Causal LM两者之间差异的解释。
2. 什么是Prefix LM?
Prefix LM,即前缀语言模型,是一种在自然语言处理领域中的自回归模型结构变体。在标准的自回归Transformer模型(如GPT系列)中,解码器仅能利用之前生成的词元来预测下一个词元,遵循严格的左到右顺序。
而在Prefix LM框架下,模型通常在一个共享的Transformer架构上进行训练和预测,它允许Encoder和Decoder部分通过精心设计的Attention Mask机制来共享权重。这个机制使得在预测过程中,解码器可以有条件地访问到输入序列的部分或全部内容作为“前缀”信息,而不仅仅依赖于已经生成的词元序列。
Google的T5(Text-to-Text Transfer Transformer)模型就引入了类似的概念,尽管不直接称为Prefix LM,但其在预训练阶段采用了所谓的“Prefix任务”,即在编码器中加入额外文本信息(例如问题或上下文),然后让解码器根据这些前缀信息生成目标输出,从而实现对多种NLP任务的统一处理。这种技术有助于模型更好地理解并利用给定的输入上下文来进行后续的文本生成或预测任务。
下面的图很形象地解释了Prefix LM的Attention Mask机制(左)及流转过程(右)。
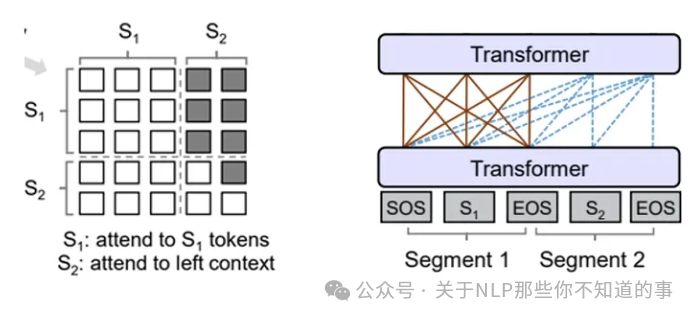
Prefix LM的Attention Mask机制(左)及流转过程(右)Prefix LM的代表模型有UniLM、T5、GLM(清华滴~)
3. 什么是 Causal LM?
了解了Prefix LM后,再来看Causal LM就简单的多了~
Causal LM(因果语言模型)是一种自回归语言模型,它在自然语言处理(NLP)领域中用于预测一个序列中的下一个词或token,基于前面已经生成的所有词。在训练和推理过程中,这种模型遵循“因果性”原则,即模型在生成每个位置的token时,只能利用序列中之前出现的部分作为上下文信息,而不能提前看到未来还未生成的部分。
例如,在GPT(Generative Pre-training Transformer)系列模型中,采用了Causal LM结构设计,其解码器部分的自注意力机制被限制为仅能查看左侧(过去)的tokens,确保了模型预测的序列性。这样的模型非常适合于文本生成任务,因为它们能够逐词地生成连贯的文本序列,并且由于其自回归特性,能够捕捉到文本序列内部的时间依赖关系。
参照着Prefix LM,可以看下Causal LM的Attention Mask机制(左)及流转过程(右)。
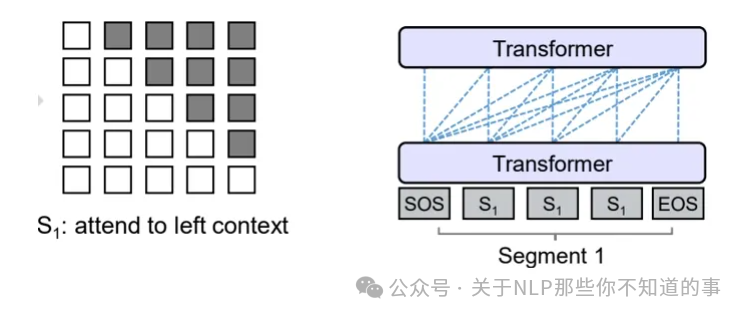
Causal LM的Attention Mask机制(左)及流转过程(右)Ps(图真是个好东西,一图胜万字呀)
4. Prefix LM vs Causal LM?
Prefix LM(前缀语言模型)和Causal LM(因果语言模型)在某些上下文中可以指代相同的概念,但通常情况下:
Prefix LM:
Causal LM:
所以,实际上,在现代NLP中的自回归文本生成背景下,Causal LM可以视为一种特殊的、更明确的前缀LM,强调其预测过程中的因果关系和时间上的单向依赖性。
5. 总结
一句话足矣~
前缀语言模型可以根据给定的前缀生成后续的文本,而因果语言模型只能根据之前的文本生成后续的文本。
6. 参考
(1) google T5: https://arxiv.org/pdf/1910.10683v4.pdf
(2) 微软UniLM: https://arxiv.org/pdf/1905.03197.pdf
(3) google理论评估PLM与CLM: https://arxiv.org/pdf/2308.06912.pdf
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
