前言
题目难度中规中矩,字符串处理题还是比较烦人的,尽量熟悉字符串的api就好了。动态规划的题目比较简单,大部分同学应该都可以完成。第三题倒是容易想到单调栈,但是实际题意却不是如此,需要慎重考虑。
春招和暑期实习的笔试也陆陆续续开始啦,有参加笔试的同学欢迎投稿哦,投稿一场完整笔试的(题面+代码),请你喝一周的奶茶的现金奖励哦!(投稿加文末微信,备注投稿)
文末也有我们的活动介绍,有兴趣参加活动也可以添加微信了解滴!
1.求和方式
给定一个正整数 s 和 n 个正整数 , 求有多少种组合的和为 s ?
数值相同的两个数视为不同的两个数。
输入描述
第一行两个整数 n,s,含义如题所述;
第二行 n 个整数。
1<=n<=30,1<=s<=900,1<=wi<=s
输出描述
输出一个整数表示答案。特别地,如果没有合法方案,输出0。
示例 1
输入
10 5
1 1 1 1 1 1 1 1 1 1
输出
252
说明
C(10, 5) = 252
思路与代码
动态规划。
核心是一个背包问题,每个元素2种选择:选和不选。
状态定义:f[i] [j] 考虑前i个元素,凑出和为j的元素有多少种组合。
状态转移:f[i] [j] = f[i-1] [j] + f[i-1] [j-a[i]]
#include <iostream>
#include <vector>
#include <map>
using namespace std;
int n, s;
vector<int> A;
map<pair<int, int>, int> memo;
int dfs(int i, int j) {
// Check if the result is already in the memo
auto it = memo.find({i, j});
if (it != memo.end()) {
return it->second;
}
if (i >= n || j > s) {
return (j == s) ? 1 : 0; // Return 1 if j equals to s, otherwise 0
}
// Recursive calls: exclude the current element or include it
int result = dfs(i + 1, j) + dfs(i + 1, j + A[i]);
memo[{i, j}] = result; // Save the result in the memo before returning
return result;
}
int main() {
cin >> n >> s;
A.resize(n);
for (int i = 0; i < n; ++i) {
cin >> A[i];
}
cout << dfs(0, 0) << endl;
return 0;
}
2.Regular Expresssion
实现简单的正则表达式匹配,本题中模式字符串所包含的字符的范围为字母、“.”、“*”、“?"
“.” 匹配任何单个字符
“*” 与模式字符串前一个字符组成一组,匹配零个或多个前面的字符
“?” 与模式字符串前一个字符组成一组,匹配一个或多个前面的字符
匹配应该覆盖到整个输入的字符串(而不是局部的),测试用例中不会出现超出匹配字符范围之外的字符,也不会出现非法的模式字符串。
使用语言提供的正则表达式库将算作无效答案。
输入描述
输入的第一行为需要检测匹配的用例数。
接下来的每一行包括两个字符串,前一个字符串为待匹配的字符串,后一个字符串为模式字符串。
待匹配字符串的长度不超过10。
输出描述
对于每一个测试用例,如果匹配则输出一行true,如果不匹配则输出一行false。
示例 1
输入
3
aa a
aa aa
aaa aa
输出
false
true
false
示例 2
输入
5
a a.
a a.*
ab .*
ab .?
b a?
输出
false
true
true
true
false
思路与代码
这个问题可以通过递归来解决,逐个字符地比较输入字符串和模式字符串,同时处理特殊字符“.”、“*”和“?”。
#include <iostream>
#include <vector>
#include <string>
using namespace std;
bool matchCore(string& str, int sIndex, string& pattern, int pIndex) {
if (sIndex == str.size() && pIndex == pattern.size()) return true; // 完全匹配
if (sIndex != str.size() && pIndex == pattern.size()) return false; // 模式串用完但字符串没有用完,不匹配
// 检查下一个字符是不是'*'或'?'
bool nextIsStar = pIndex + 1 < pattern.size() && pattern[pIndex + 1] == '*';
bool nextIsQuestion = pIndex + 1 < pattern.size() && pattern[pIndex + 1] == '?';
if (nextIsStar) {
if ((sIndex != str.size() && (pattern[pIndex] == str[sIndex] || pattern[pIndex] == '.')) ||
(sIndex == str.size() && pIndex + 2 == pattern.size())) {
// 移动字符串或模式串,或者两者都移动
return matchCore(str, sIndex + 1, pattern, pIndex) ||
matchCore(str, sIndex, pattern, pIndex + 2) ||
matchCore(str, sIndex + 1, pattern, pIndex + 2);
} else {
return matchCore(str, sIndex, pattern, pIndex + 2);
}
} else if (nextIsQuestion) {
if (sIndex != str.size() && (pattern[pIndex] == str[sIndex] || pattern[pIndex] == '.')) {
// 匹配一个字符,然后移动模式串和字符串
return matchCore(str, sIndex + 1, pattern, pIndex + 2);
} else {
return false; // '?''前的字符必须存在且匹配
}
} else if (sIndex != str.size() && (pattern[pIndex] == str[sIndex] || pattern[pIndex] == '.')) {
return matchCore(str, sIndex + 1, pattern, pIndex + 1);
}
return false;
}
bool match(string& str, string& pattern) {
return matchCore(str, 0, pattern, 0);
}
int main() {
int n;
cin >> n;
while (n--) {
string s, p;
cin >> s >> p;
cout << (match(s, p) ? "true" : "false") << endl;
}
return 0;
}
3.野猪骑士
野猪骑士最近在一条路上锻炼,整条路可以被分作n块地块,每个地块有自己的高度i。野猪骑士在地块i时,会跳向 下标比i大 且 高度比hi严格大的地块的集合中,高度最小的地块。
野猪骑士希望知道自己在每个地块上的下一跳的目的地的高度,如果下一跳不存在的话,则记为-1。但这对野猪骑士来说太难了,他希望你来帮助他。
更形式化地说,给定一个数列h, 求一个数列d,其中如果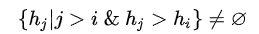
输入描述
第一行包括一个正整数n,第二行包含n个正整数h1,h2,...,hn。
输出描述
一行,包括n个正整数d1,d2,...,dn
补充说明
PS:
- 由于本题输出较多,使用java的同学尽量使用StringBuilder,一次性输出答案,否则容易超时。
- 由于本题输出较多,使用C++的同学尽量使用printf,或者关闭同步流,否则容易超时。
示例 1
输入
4
4 1 2 3
输出
-1 2 3 -1
示例 2
输入
7
11 13 10 5 12 21 3
输出
12 21 12 12 21 -1 -1
思路与代码
主要思路是红黑树 。部分语言没有红黑树的就要自己找一个有序、可删除元素的数据结构进行替代。
从前往后遍历,对于每一个元素,在红黑树上查找大于当前元素的最小值,遍历完这个元素记得删除这个元素。
#include <iostream>
#include<set>
#include<map>
using namespace std;
int n,arr[100010], ans[100010];
int main() {
int n;
cin.tie(0);
cin >> n;
set<int> s;
map<int, int> mm;
for (int i = 0 ; i < n ; i++) {
cin >> arr[i];
if (i != 0) mm[arr[i]] += 1;
}
auto it = mm.upper_bound(arr[0]);
if (it != mm.end() ) ans[0] = mm.upper_bound(arr[0])->first;
else ans[0] = -1;
for (int i = 1 ; i < n ; i++) {
auto it = mm.upper_bound(arr[i]);
if (it != mm.end() ) ans[i] = it->first;
else ans[i] = -1;
mm[arr[i]] -=1;
if (mm[arr[i]] == 0) mm.erase(arr[i]);
}
for (int i = 0 ; i < n ; i++) cout << ans[i] << " ";
}
// 64 位输出请用 printf("%lld")
4.Integer Encoding
Protocol Buffer 是 Google 的一种用于网络数据传输的序列化库,其对整数采用变长编码的方法。整数从低位向高位输出,每次输出一个字节,该输出字节中含有源整数的7bit 信息,输出字节的最高位用作标志位,1表示继续,0表示结束。
输入描述
第一行包含一个正整数 n
第二行包含一个正整数x编码后的字符串
输出描述
第一行包含正整数n编码后的结果
第二行包含解析出来的正整数x
补充说明
编码数据为16进制字符串
字母大写 整数n, x都是无符号64bit整数
示例 1
输入
100
0XE70X07
输出
0X64
999
说明
100 = 0x64 = 0b01100100; 低位7bit为0b1100100 = 0x64,高位没有剩余为1的bit,所以输出字节最高位为0,编码结束,结果为0x64
0xe7 = 0b11100111; 取低7bit,x = 0b1100111 0x07 = 0b00000111; 取低7bit放在x的高位,x = 0b00001111100111; 由于0x07最高bit为0,表示这是最后一个字节,所以x = 0b00001111100111 = 999
思路与代码
主要思路是位操作和字节处理。部分语言没有直接支持变长编码的库,就要自己通过位操作,进行编码和解码。
从整数n的编码开始,对于每一个7位的分段,在位操作上进行处理。编码过程如下:
- 提取最低有效的7位:从整数的最低有效7位开始,每次处理7位。
- 设置字节标志位:将这7位放入一个字节的低7位中,如果还有更多位待处理,就将这个字节的最高位设置为1,表示后续还有数据;如果没有,设置为0,表示这是最后一个字节。
- 转换为16进制字符串:将每个处理过的字节转换成16进制字符串,以符合输出格式。
- 重复直到完成:继续处理剩余的位,直到整数的所有位都被编码。
解码过程也同理:
- 读取每个编码字节:将编码字符串的每个字节转换回二进制格式。
- 处理字节标志位:检查每个字节的最高位,如果为1,表示还有后续字节;去除最高位后,将剩下的7位放置到结果整数的适当位置。
- 完成解码:如果某个字节的最高位为0,表示这是编码的最后一个字节;同样去除最高位后,将剩下的7位添加到结果整数中,结束解码过程。
#include <iostream>
#include <vector>
#include <string>
#include <sstream>
#include <iomanip>
// 将整数编码为Protocol Buffer变长编码的16进制字符串
string encode(unsigned long long n) {
vector<unsigned char> bytes;
do {
unsigned char byte = n % 128 + (n >= 128 ? 128 : 0); // 判断是否需要设置最高位为1
bytes.push_back(byte);
n /= 128;
} while (n > 0);
stringstream ss;
for (auto it = bytes.rbegin(); it != bytes.rend(); ++it) {
ss << "0X" << uppercase << setfill('0') << setw(2) << hex << static_cast<int>(*it);
}
return ss.str();
}
// 从Protocol Buffer变长编码的16进制字符串解码为原始整数
unsigned long long decode(string& encoded) {
unsigned long long x = 0;
int shift = 0;
for (size_t i = 0; i < encoded.length(); i += 4) { // 每次处理一个编码字节
string byteStr = encoded.substr(i + 2, 2); // 获取两个字符,表示一个字节
unsigned char byte = stoul(byteStr, nullptr, 16);
x |= static_cast<unsigned long long>(byte & 0x7F) << shift; // 应用低7位
if ((byte & 0x80) == 0) break; // 如果最高位为0,则终止
shift += 7;
}
return x;
}
int main() {
unsigned long long n;
string encodedX;
cin >> n;
cin >> encodedX;
// 输出n的编码结果
cout << encode(n) << endl;
// 解码并输出x的原始值
cout << decode(encodedX) << endl;
return 0;
}

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
